A little over 10 years ago, in a previous role/company, I designed and implemented a website hosting environment (with a catchy name of “w 3 p cloud”) to ….
- support WordPress/LAMP like environments
- have some sort of process/file isolation between sites, so a malware infection in one shouldn’t be able to spread/reach other sites
- have resource limits in place (the business also liked the idea of charging for more “firepower”, I just wanted to try and stop one site from doing a denial of service on others)
- be hosted in AWS (EC2) because it was cool to be moving to the cloud (despite the cost)
Eventually, I settled on using LXC containers with a Varnish server as a HTTP frontend router. Hosting within AWS (EC2) was basically a non-negotiable requirement and there weren’t many alternatives either.
A crude web UI was added for managing sites, which was quickly adapted to have a JSON API on top. Then background tasks were added – involving a job queue (originally gearman, later on beanstalk) and some management of iptables rules.
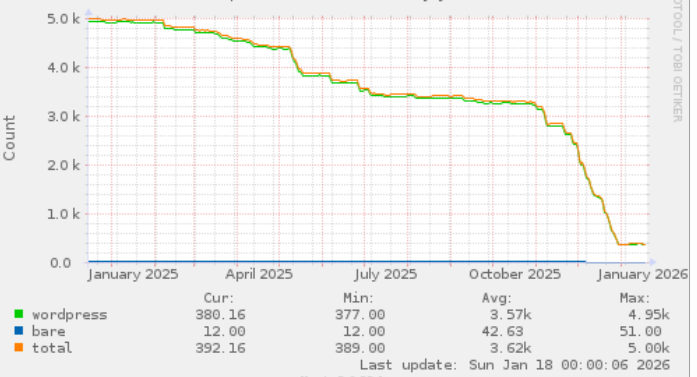
Fast forward to 2026, and it’s still (just about) in use.
As a programmer/developer, we often don’t think too much about the distant future when creating something. We’ve got immediate deadlines, and thinking more than 2-3 years is difficult. There are plenty of uncertainties in life afterall!
Over the years, there have been multiple upgrades of various bits (Varnish, PHP, Debian release, Linux kernels etc).
I think it had between 5-8k sites at it’s peak, and I often found it amusing when I realised I was ordering/using a website hosted on it as a member of the public.
Anyway, all good things come to an end, I guess …. and finally a migration to something bigger/better/faster/shinier has begun, as this count of sites being hosted in it shows: